
Let the Data Flow: Testifying at the 4th COGE Public Hearing
Or, evangelizing Claude Fable 5, thinking about law as code, and a provocation articulating the case for AI legal drafting


On May 28, Mayor Zohran Kwame Mamdani announced the convening of a Charter Revision Commission called COGE, or the Commission on Government Efficiency. My friend Daniel Golliher has written a splendid primer for Maximum New York on what COGE, Charter Revision Commissions, and the sources of law the Mayor derives his authority from to convene them, and you should probably read his piece before mine if you are new to the idea of a Charter Revision Commission.
Throughout the summer, COGE will be hosting a series of public hearings, inviting members of the public to testify on their plethora of ideas of innovating the City’s statecraft and expanding its administrative capacity to build our world, as we once did, and as we are obliged to continue to do. It is plausible to claim that the roots of this initiative, which have undoubtedly been percolating in the new Mayor’s head for some time, are in then-candidate Mamdani’s podcast conversation with Derek Thompson, co-author of Abundance with Ezra Klein.
I had not started the week planning on testifying to COGE this early in the hearing schedule, but three events this week coalesced into my written testimony that I plan to submit to the fourth COGE public hearing, to be held later today at Brooklyn Law School (if you also are attending, please say hello):
Two days ago, I attended an informative roundtable call hosted by Abundance New York and Maximum New York on COGE, and how one goes about testifying to the Commission. These are not only fantastic organizations and publications to learn New York City civics from, but additionally beneficial in the compounding network effects of being around highly ambitious, agentic, and smart people in politics.
In most opportune timing, BetaNYC, a civic tech organization, recently launched a suite of Model Context Protocol servers, or MCP, for integrating large language models like Claude or ChatGPT. Sans technical parlance, MCPs are tools that act as a plug between AI large language models and data; in this case, the data is the sources of New York City law: the Charter, Administrative Code, and Rules. These are radically force-amplifying tools for legal analysis that compress research timelines from months to mere hours.
Anthropic’s Claude Mythos-class Fable 5 model dropped earlier this week, which appears to be so apotheotic in its abilities that it recreated Minecraft in a single prompt.
Taking the trifecta of peer inspiration, new toys, and a entirely new class of model to tinker with, I wanted to see how far I could push legal and policy analysis in the compressed timeline of a single night.
I facetiously tell people I am semi-retired from legislative politics. There are other endeavors I wish to pursue with my life, but inevitably I find myself returning to a legislative forum one way or another. But in my past life, I spent half of my twenties as a legislative staffer in the New York State Assembly, and cut my teeth in legislative policymaking through the paroxysm of the pandemic.
In those days I authored a fair share of legislative bill drafts, the most impactful of which was a bill that subtracted, not added statute: the repeal of legal immunity for nursing home operators, surreptitiously inserted into the state budget at the outset of the pandemic in 2020 by the Cuomo administration. That said, like two-thirds of members of Congress, I am bereft of any formal legal credential. Everything I know about law was learned on the job, or in my reading of cases and American law books over the years.
Moreover, in my day, we had no sophisticated LLMs to conduct legal research with. Only this lovely interface! During my first week of the legislative session in 2020, I applied for a staffer New York State Library card, and in my unadulterated naivety, I searched for a physical set of McKinney's Consolidated Laws of New York Annotated to own and markup and study from, only to lament its prohibitive pricing. Legal research was painstaking and tedious, with no obvious on-ramp to acquaint oneself with the institution.
Today, the landscape is unrecognizable.
At its core, law is code. There have even been academic attempts at building machine programming languages for law, like Catala, which translates statutory law into implementable code. Treating bodies of law as disparate as the United States Internal Revenue Code and the French family benefits system as algorithmic in nature, the authors attempt to formalize law as a self-consistent logic, akin to the architecture of a machine programming language.
Central to the mechanics of a coherent law, and arguably to the notion of justice itself, is predictability. Particularly, it is the guarantee that the same facts in a case beget the same legal holdings. Morton Horwitz, one of the nation’s preeminent legal scholars, writes in the magisterial first volume of The Transformation of American Law about the enshrining of consistent precedents in 1790s maritime commercial arbitration cases, a prerequisite to the reliable development of the young American Republic’s fledgling sailing industry. As anyone who has interfaced with investors knows, there is nothing that makes the titans of commerce more skittish than unpredictability in business contracts.
Code, categorically, functions similarly. You would not want most of your computer functions to exercise probabilistic or otherwise inconsistent behavior: imagine if clicking on your mouse or tabbing on your keyboard led to a different outcome each time. Such a device would have its utility only in comic relief. The internal logic of code, like law, is premised on determinism to work.
Code as Law, Law as Code
Accepting that law is analogous to machine code in its internal logic, one natural yet provocative experiment follows: if code generation can be automated with large language models, can legislative drafting?
In my experience, the thought tends to stir up strong aversion. But there is no doubt that frontier large language models simply outclass any human programmer, no matter how innate and formidable their talent. Where an LLM can rapidly build context and understand dependencies and relationships within a codebase’s architecture, a human’s cognitive tax grows with the codebase’s sprawl.
Law is no different, with definitions, dependencies, and constraints imposed by one body of statute on another running rife throughout any corpus. Appealing to an argument of scale, the Code of Federal Regulations alone spans nearly two-hundred-thousand pages of text. It is at best a colossal waste, and most realistically cognitively impossible, to expect a group of people to successfully parse through the accumulation of law across all tiers of United States government, identifying its internal inconsistencies.
Therefore, I hypothesize: a frontier LLM, like Claude Fable 5, can do it better.
The experiment
To test this hypothesis, I installed BetaNYC’s MCP for New York City law, spun up a new agent in the command line, and thought about data interoperability problems I have been experiencing in my fiscal policy research. Specifically, New York City budget data is not clean to work with when conducting longitudinal studies of granular budget items, as labeling for certain budget codes can be inconsistent over time. Additionally, documents like the Annual Comprehensive Financial Report (ACFR) do not have accompanying spreadsheets prior to 2022, which means a researcher is consigned to attempt to extract the desired data from a PDF. Naturally, my curiosity went to wondering if the City Charter has any mention of “machine-readable” or “structured” data.
Ergo, I gave the following prompt:
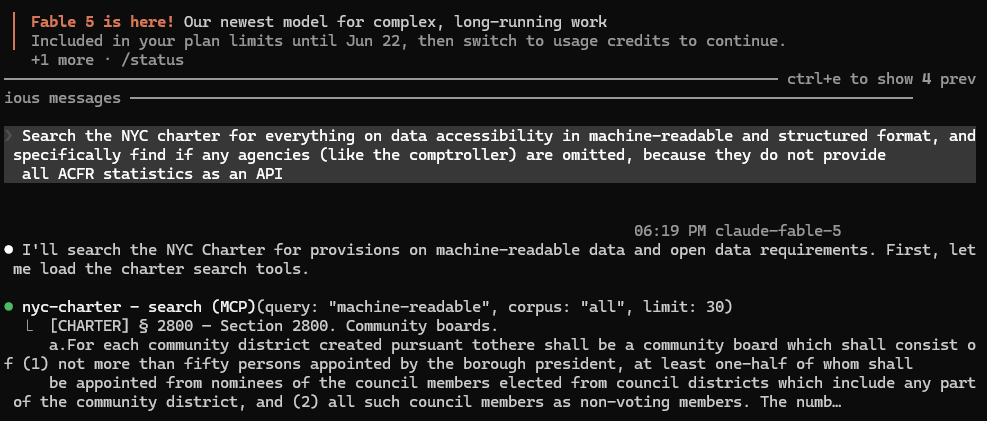
And after a minute or two, Claude came back with an amazingly satisfying output:
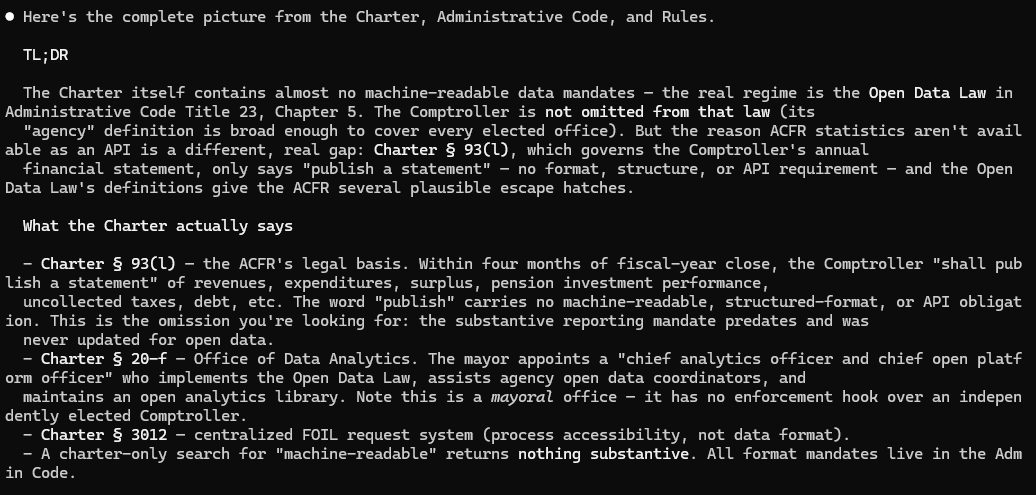
In no more than two minutes, Fable 5 returned the key clause I was searching for: Section 93(l), which is one part to the promulgation of the New York City Comptroller’s duties in the organic law. After some more volleying and uncovering additional relevant language in the Charter, I prompted Claude to summarize our discussion into a list of proposed amendments to the Charter itself. In other words, I asked Claude to play a legislative drafter.

The abridged result, which is filtered through my (human, and therefore imperfect) understanding of how the Charter works, is what I have appended to my written testimony to the Charter Revision Commission. You can view Claude’s handiwork here, which will be the final document I plan to submit to COGE. Again, I am no lawyer, but a substantial chunk of my twenties was spent reading legalese, and Claude’s ability to write in legalese is stunning prima facie.
I do not ever use AI to write my Substack posts, emails, or any writing meant to have soul, wit, and compassion for people. But from my twelve-hour experiment, with one hour expended on a frontier model with an unfathomably large number of machine neurons and weights, and the remaining time composing my testimony and this post, with my biological neurons that I’ve known and loved for life, I cannot deny the advent of a paradigm shift that those of us at the crossroads of science, technology, and policy find ourselves in.
Whether my (or Claude’s) thoughts have any value in this Charter Revision Commission will solely be left to the commissioners — and whichever questions they converge on, the New York City electorate come November. That human element is here to stay. Where some in our line of work may be wont to reflexively retreat from the inexorable march of the future, I argue that we cannot ignore it, and that if we are to be duly intentioned in our service to the body politic, we must embrace it.
Finally, my testimony below.
Testimony to the New York City Charter Revision Commission — Brooklyn Hearing 1: Modernizing Government and Streamlining Government Technology
Transparency and accessibility to public data are the paramount priorities of effective digital governance. In the recent decade, the City has made strides towards the ideal of intuitive data infrastructure, particularly in the enactment of Local Law 11 of 20121 (the “Open Data Law”) under Mayor Michael Bloomberg, giving rise to NYC Open Data. Subsequent statutes, such as Local Laws 37 and 38 of 20142, mandated digital and machine-readable publication of the sources of City law (the Charter, Administrative Code, and Rules of the City) and The City Record, respectively.
In the spirit of continuing to maintain the inexorable march towards full data openness and facilitating efficiency of governance in the digital realm, I propose three amendments to the Charter for the Charter Revision Commission to consider. These proposals are intended to provide a systematic approach towards building a state-of-the-art data infrastructure fit for the age of AI, and to offer an incremental step towards fully empowering New Yorkers to understand and hold their City government to account.
Impose machine-readability requirements for the Annual Comprehensive Financial Report in adherence to federal law. Under § 93-l of the Charter, the Comptroller is required to “publish a statement” detailing the City’s revenues and expenditures and its sources, the state of the general fund stabilization reserve fund, debt service and other matters pertaining to the City’s fiscal state. This document is commonly called in public finance lingo the Annual Comprehensive Financial Report, or ACFR, and has historically been an unwieldy document largely inaccessible to all but devoted disciples of fiscal policy minutiae.
Critically, the ACFR is the only source in the myriad of the City’s fiscal policy publications that lists the actual revenues and expenditures of the City for each fiscal year, a level of specificity that none of the Preliminary, Executive, and Adopted budgets published by the Office of Management and Budget under the mayoralty reach.
The motivation for this proposal is not exclusive to the public interest. There is also an impending federal requirement to publish ACFR data in structured and machine-readable format. Pursuant to the Financial Data Transparency Act of 20223, which amends the Securities Exchange Act to require machine-readable data for municipal securities disclosures, the Securities and Exchange Commission (SEC) is in the process of promulgating data standards that all municipalities in the business of bond issuance must adhere to. As home to several such bond-issuing authorities (the Transitional Finance Authority and the Municipal Water Finance Authority, to name two), the City and its authorities extensively file with the Municipal Securities Rulemaking Board (MSRB) Electronic Municipal Market Access (EMMA) system.
Although the rulemaking4 process by the SEC remains underway with the specifics of data structuring requirements still outstanding, in anticipation of new rules, the City should enshrine in its charter clear mandates for data standards to accompany publication of the Annual Comprehensive Financial Report by the Office of the Comptroller. Fortunately, former Comptroller Brad Lander instituted for the FY2022 ACFR the practice of providing the financial and statistical tables available for download.5 However, due to the importance and centrality of the ACFR in crafting fiscal policy, specifying structured, machine-readable publication of ACFR data as a Charter requirement should be taken into consideration by this Commission.
Recommendation:Amend § 93(l) of the Charter to mandate the publication of bulk structured and machine-readable data alongside the Annual Comprehensive Financial Report.
a. Require more granular subdivisions of expense budget data beyond the unit of appropriation.
b. Mandate consistent data ontology that facilitates long-term studies of City fiscal policy; particularly, stable labeling of units of appropriation and budget codes over time through the creation of a schema crosswalk.
Data for the expense budget, published by the Mayor’s Office of Management and Budget (OMB), is structured in varying levels of granularity. The hierarchy, beginning at agency-wide summaries, progresses down to units of appropriation (U/A), consisting of personal service (PS) and other than personal service (OTPS) spending, which subdivides once more into discrete budget codes.
In certain publications, such as the Expense Funding — All Source document6, the budget code subdivision is absent. Budget data that is bereft of total disaggregation of a unit of appropriation’s components inhibits the City’s objective of transparency. A simple amendment to the corresponding Charter clause, codified in § 100, can rectify this omission of critical budget data presentation.
Furthermore, longitudinal studies of fiscal policy trends in New York City are profoundly complicated by inconsistencies in the OMB’s labeling of units of appropriation and budget codes. This makes true semantic consistency of similarly-named U/As an unnecessarily laborious matter to resolve, and risks introducing inaccuracies into the analyses on which fiscal policy decisions rest. A budget ontology that rigorously links budget items to their hierarchy, source of funding, and otherwise makes these semantic relationships unambiguously clear would greatly aid policymakers and the public in coming to informed conclusions about the budgetary process.
Recommendations:Amend § 100(c) of the Charter to require subdivisions beyond the unit of appropriation in all budget publications.
Add a new section § 100(i) of the Charter to establish a rigorous ontology for budget data.
Eliminate bottlenecks in inter-agency data-sharing that are created by the requirement for memoranda of understanding. Data must not only be transparent; it is semantically useful only when it is interoperable between systems. Agencies must frequently engage in data-sharing among themselves in rendering service delivery. Institutional frictions, however, hinder the effectiveness of the state. Consequently, the aggregate administrative capacity of the government is weakened with personnel consigned to duplicative data management efforts, cross-agency collaboration incurs steep transaction costs due to the paucity of interoperable data, and government responses to acute crises (such as the COVID-19 pandemic) become sclerotic.
Currently, city agencies codify data-sharing agreements in the form of a memorandum of understanding (MOU). Although these can help establish guardrails to protect individual privacy and safeguard personally identifiable information (PII), the process of negotiating an MOU is lengthy and tedious, and sacrifices agility and force-amplifying response to acute problems for sluggish procedure.
A City & State article from November 20227 underscores that the appetite to substantively implement a unified data sharing infrastructure was strong as recently as the last mayoral administration. The tension between ubiquitous data sharing and constituent privacy, however, need not be seen as zero-sum at all. In this, Jennifer Pahlka writes8 in Eating Policy about how the tension between privacy and fluidity in data flows can be balanced with thoughtful engineering of application programming interfaces, or APIs:But not being able to export all the data in a system is why APIs exist. APIs are designed to provide specific, limited functionality through predefined endpoints with proper authorization controls. They’re meant to facilitate secure, controlled data exchange between systems. Properly designed APIs include: authentication (verifying identity), authorization (permission levels), rate limiting (preventing excessive requests), data filtering (returning only necessary information), and audit logging (tracking all access). A core principle of API design is to return only the data needed for a specific task, not entire databases. (For example, an agency might need to know if a company filed taxes in the previous year. An API might return a simple yes or no without divulging other sensitive information.)
Recommendation:
Amend chapter 48 of the Charter to include a new § 1077 on inter-agency data sharing, minimizing institutional and legal frictions in coordinating and standardizing semantic interoperability, while protecting constituent privacy.
15 U.S.C. §§ 78o–4(b), as amended Pub. L. 117–263, div. E, title LVIII, § 5823(a), Dec. 23, 2022, 136 Stat. 3427
As of June 8, 2026, the Securities and Exchange Commission has established joint data standards as a means of “promot[ing] interoperability of financial regulatory data across the agencies by establishing common identifiers for entities, geographic locations, dates, and certain products and currencies.” See press release no. 2026-53.
Expense Funding — All Source, New York City Mayor’s Office of Management and Budget.